

Even the most basic carpenter plans before building. But there's a different kind of carpentry job that is not about building something new. It's about renovating a house someone is already living in.
The plumbing is already there. The walls are already up. The wiring follows whatever code was current when it was installed. The owner is still using the kitchen while you're working on it. Every cut you make has consequences for systems you didn't build and don't fully understand. That's brownfield work, and the principles are different than greenfield in ways that matter.
In the second post of this series, I argued that AI compression on greenfield work comes from compressing the spec phase enough that the build runs uninterrupted, the way the hammers-and-nails philosophy always intended. Brownfield is a different case entirely. The build phase doesn't run uninterrupted, because the build phase is happening on a system that's already running. The compression lives somewhere else.
The Setup
A long-running content management system. Plugin-based architecture. Permission system mid-migration from a legacy access model to a new one. Roughly 54 files in active scope. No test suite to speak of. Live production traffic.
This is the canonical brownfield setup. A codebase too large to hold in one head, with a mix of legacy and new patterns.
Here is the part that gets missed by every AI-bullish consultant:
An analysis can be 99 percent accurate about where to make edits, and the edits themselves can be locally correct, and the system can still fail because the codebase carries coupling the analysis cannot fully see.
The mistake AI consultants keep making on brownfield work is treating edit accuracy as the risk. It is not. The risk is ripple. One edit can cascade through paths the original code review missed entirely. One correct change can unmask three latent issues. That is not a probability you compound. It is a structural property of long-lived production systems.
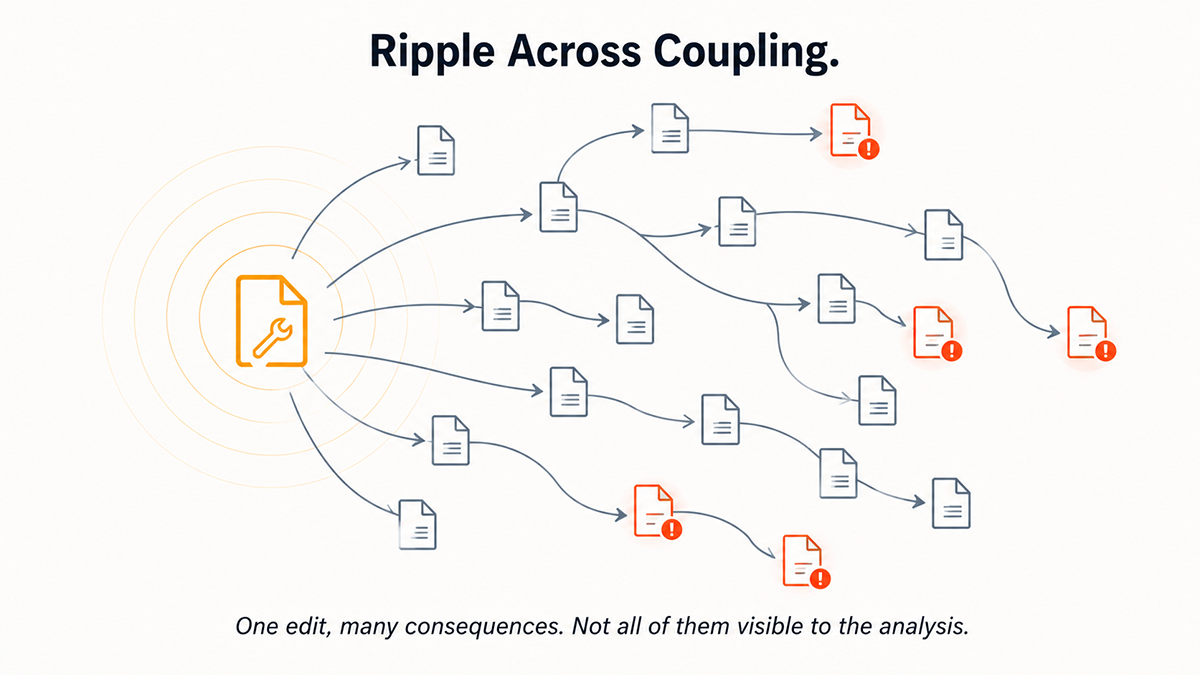
Which is why the compression on brownfield doesn't live in code generation. It lives in analysis.
The Shape That Keeps Repeating
| Phase | Time before AI | Time with AI | Risk profile |
|---|---|---|---|
| Inventory and impact mapping | Days of grep and manual reading | Minutes | Low, read-only |
| Root-cause diagnosis | Hours to days, often misdiagnosed | Minutes once context is loaded | Low, read-only |
| Remediation plan drafting | Days of writing | Minutes | Low, document only |
| Applying edits at scale | Days of careful work | Same or worse if AI drives | High, cascading failures |
The first three rows are where weeks compress into hours. The fourth row is where untriaged AI edits cause site outages.
A few moments from this engagement made the asymmetry concrete.
Where AI Compressed the Work
The deeply baked legacy concept. The legacy access model was woven through the codebase in ways that made any global change unacceptably dangerous. The same concept appeared in data access layers, in business logic, in rendering paths, in admin tooling, and in places that should not have been touching it at all. A naive find-and-replace would have broken production in dozens of places, some of them obvious and some of them subtle. AI mapped every entanglement, including references that the original code review had missed entirely, and surfaced a few callers that turned out to be orphaned (their results were assigned to variables nobody read). That mapping became the input to a phase-by-phase remediation strategy, where each phase touched a bounded subset of files and could be tested in isolation. Pre-AI, identifying every entanglement is a multi-day grep-and-read exercise that almost always undercounts. AI did it in a single pass. Pure analysis. Read-only. The kind of work where AI is dramatically faster with no downside.
The permission inversion bug. A two-sided defect where the User Manager UI showed all toggles off while the runtime granted full access. AI traced it to two failures: the read path defaulted to true when no row was found, and the write path only wrote a row when at least one toggle was on, so "all off" silently wrote nothing. The diagnosis (an inversion bug requires fixes on both sides, not one) is the kind of thing that takes a senior engineer hours of staring at a debugger. AI surfaced it in the same session that surfaced the symptom.
The merge conflict cascade. A site-down incident misdiagnosed across four error layers before the actual cause was found: an unresolved Git merge conflict left in a source file. AI was instrumental in walking the cascade (parse failure to factory init to application start to error handler to rendering layer to second latent bug in the error path). The post-mortem and the preventive measures (pre-commit grep hook for merge markers, error-path resilience theme, baseline checklist) were AI-authored. This kind of layered diagnosis is exactly where AI's pattern-matching across many files at once beats a human reading one file at a time.
Where AI in the Driver's Seat Created Risk
A clean refactor that took down the site. Remove an old method from a class because the new permission model replaces it. AI executed the removal. What was missed: the rendering layer still called the old method on every admin page. Result: every admin page threw, the error handler tried to render, and the error path itself triggered a second latent bug. The lesson is not "AI got it wrong." The lesson is that a method removal in a brownfield codebase has a transitive blast radius that requires a grep sweep before the removal, not after. The remediation plan now mandates a "pre-phase grep report" as a non-negotiable first step for any phase that removes a method or column.
A misdiagnosis that almost shipped. The same site-down incident was first diagnosed by AI as a framework-level contract issue. The proposed fix (defensive hardening of an undefined variable case) was correct as defense-in-depth, but it was not the root cause. The actual root cause was the unresolved Git merge markers, which AI only identified after I pushed back and shared the actual error message. Without that intervention, we would have shipped a defensive patch around symptoms while the merge conflict remained in the file. AI's natural inclination on partial information is to rationalize a plausible-sounding fix.
Over-engineering that needed rejecting. Multiple instances where AI proposed elaborate solutions I had to cut down. A new application-scope cache when three lines using already-in-scope data was the right answer. A DDL change and migration when three hardcoded IDs in code with a comment was the right answer. Hypothetical framework-level routing that did not exist when the actual restore in the legacy code was a one-line URL parameter. Each of these would have shipped if I hadn't pushed back. Each represents a class of brownfield risk: AI's bias toward novel abstractions over the pattern already present in the codebase.
The Pattern Underneath
The pattern across all of these is the asymmetry between analysis and edits, and why ripple is structural.
Reading a codebase to map every reference, every dependency, every implicit relationship is read-only work. Every file can be examined independently. No state changes. The answer is a union of facts. AI is dramatically faster at this kind of work because nothing breaks while it is happening, and the throughput scales with compute.
Edits are the opposite. Each one changes state. Each one might trigger a parse failure that breaks an unrelated module, remove a symbol that has callers the analysis missed, conflict with an in-flight change, or violate an implicit assumption not captured anywhere in the code. The ripple cannot be predicted with certainty in advance, because the analysis only sees what the code reveals. The coupling that does not reveal itself in static reading is precisely the coupling that bites at edit time.
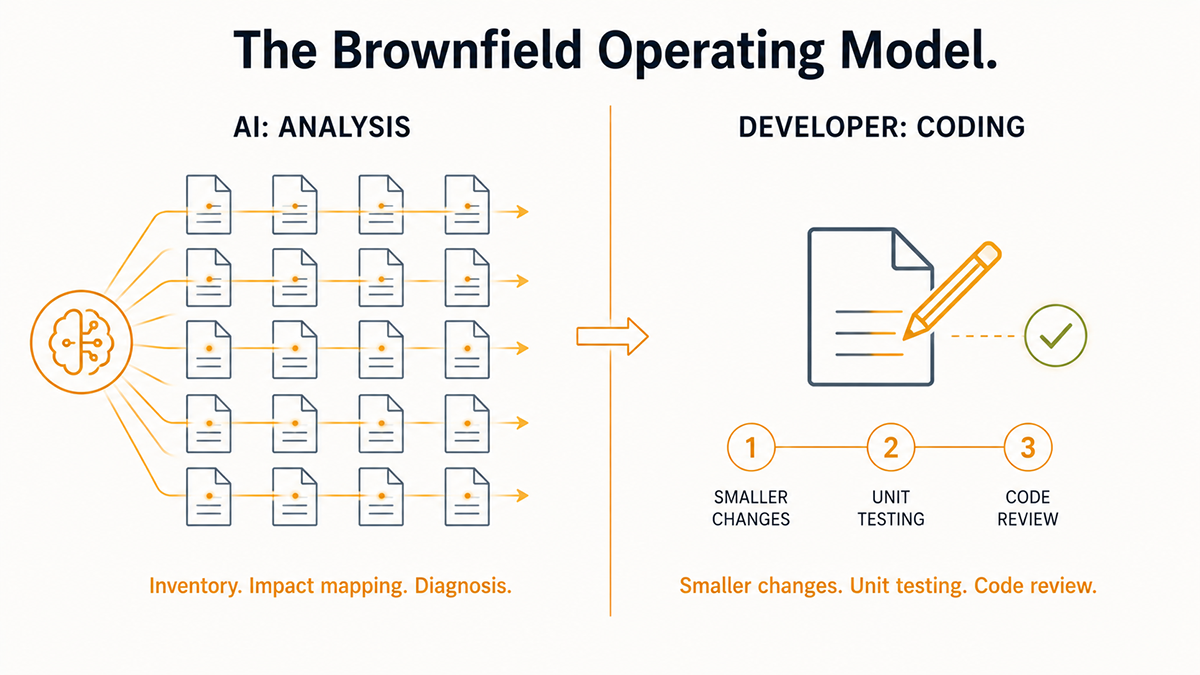
This is why the operating model on brownfield has to split the work between AI and the developer. AI does the analysis. The developer does the coding. Not because AI cannot generate code, but because generating code is the part that triggers ripple, and ripple is the part the analysis cannot fully predict.
A Scoping Note for Practitioners
The first weeks of a brownfield AI engagement are not slow because the team is slow. They are slow because the AI cannot generate good analysis until it understands the existing system. That work is real and it needs a line item.
Pricing brownfield AI work as if it were greenfield AI work is a category error. Greenfield gets faster on the build phase. Brownfield gets faster on the analysis phase. The total compression is comparable, but the shape of the engagement is completely different.
On brownfield, AI cannot do everything, and the line is clear. AI does the analysis. The developer does the coding. The experienced developer's job is to pick where AI gets involved and where to take over. That judgment, knowing what AI is good at and where it becomes dangerous, is the skill that separates senior developers from junior ones on this kind of work. A junior developer with AI on a brownfield codebase is faster than a junior developer without AI, but they will still take down production. A senior developer with AI is faster than a senior developer without AI, and the system stays up.
Someone reading this is about to argue that better test automation solves the problem. Why not have AI write comprehensive tests that catch ripple effects before they ship? It is a fair question, and on a codebase with a mature test suite it is partly correct. The problem is that most brownfield projects do not have a mature test suite. They have whatever tests existed when the team last had time to write them, which is usually not much. Writing a comprehensive test suite from scratch is itself a major project, and one that has to be done before the AI-assisted modernization can safely begin. So the "let AI write the tests" argument runs into the same brownfield friction it was meant to solve. The safety net most people assume exists is not there. That is part of why brownfield is structurally harder than greenfield.
The right operating model is AI as the analyst and plan author, the developer as the one who decides what actually changes. The discipline is what catches the cascades the analysis missed. Smaller changes. Unit testing after each one. Careful code review at each step. Anyone selling brownfield modernization as a "let AI do the work" engagement is selling a project that is about to take down a production system.
The Closing Thought for This Post
Brownfield work is where the AI hype runs into the wall hardest. Not because AI is bad at it, but because brownfield is exactly the kind of work where the rate-limiting step is the part AI cannot fully own. The keyboard work. The actual edits. The surgical discipline required to change a system that is already running without breaking the people who depend on it.
The compression is real. The win is just quieter than the greenfield win, and it lives in the analysis rather than at the keyboard.
The next post in this series turns to a third project type, one that pre-AI almost never made economic sense and now is going to drive a substantial portion of enterprise software work for the next several years. Stack migration. Rebuilding a working system on a different technology entirely.


